GCP AutoML Visonの学習済みモデルとTensorFlowでAI画像推論する
はじめに
前回、Google AutoML Visionを使って「AI画像解析でイメージカラーを抽出する」を紹介しました。(手順詳細はこちら) 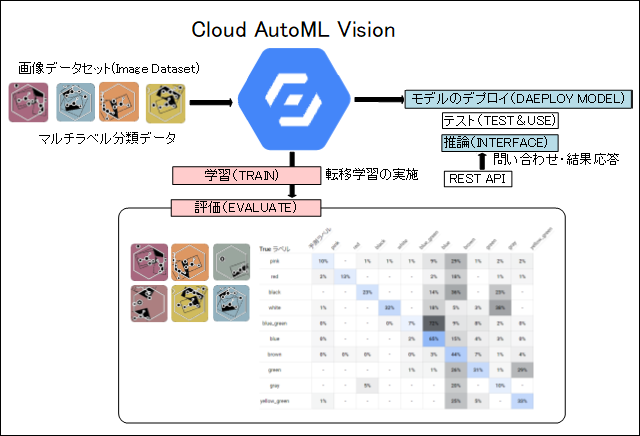
GoogleのAutoML Visionはあらかじめ用意されている学習済みの画像認識モデルを利用し、そのモデルを土台として一部を変更することで、新しい問題に対応できる機械学習サービスです。
この学習方法は転移学習と呼ばれます。ユーザはラベル付き画像データをAutoML Visionに投入するだけです。AutoML Visionはそのデータセットを元に「教師あり学習」を実行し、未知のパターンを認識するよう学習する。
ユーザはデータセットさえ用意できればゼロから画像認識モデルを開発する必要がなくなります。
今回はこのGoogle Cloud AutoML Visionで生成した新たな学習済みモデルをcloud上にデプロイせずにPC端末にエクスポートして、プログラミング言語のPythonと機械学習ライブラリのTensorFlowを用いてPC端末側で推論します。cloud上で推論せず自身のPCやIoT機器単独で推論できるようになります。
※TensorFlow はGoogleが開発したオープンソースの機械学習ライブラリです。
TensorFlowの学習済みモデルのファイルであるsaved_model.pbを用意済みで、具体的な手法を参照されたい方は、5.TensorFlowモデルのsaved_model.pbから読み進めてください。
Auto MLのCloudホストとedgeモード
Google Cloud AutoML Visionにはcloudホストとedgeモードの2種類があります。cloudホストは学習(TRAIN)、評価(EVALUTE)、テスト(TEST&USE)、推論(INTERFACE)全てをクラウド上で行います。またAPI連携によってオンラインで推論も可能です。
それに対してedgeモードは学習(TRAIN)、評価(EVALUTE)を行い学習済みデータの生成はフェーズまでとなります。推論はこの学習済みデータをエクスポートしてPCやIoT機器側でTensorFlowを用いて実施できます。
クラウドAI(Cloud AI)に対して端末側で推論する方法としてエッジAI(Edge AI)と言われます。IoT等の端末側で推論することでリアルタイムな判断ができます。ただし、端末側で行うのでその学習済みモデルは軽量なもので、高度な計算・判断は難しいデメリットがあります。
前回はモデルの定義と推論はcloudホストで行っていました。画像認識モデルの場合は学習済みデータをエクスポートできません。edgeモードで学習済みデータをエクスポートする必要があります。
cloudホストで実施[Fig1]したことを再度、edgeモデルでやり直しました。edgeモデルでは最適化に高速、中間、高精度の3種類あり高精度(Higher accuracy)でモデル作成しました。[Fig2]
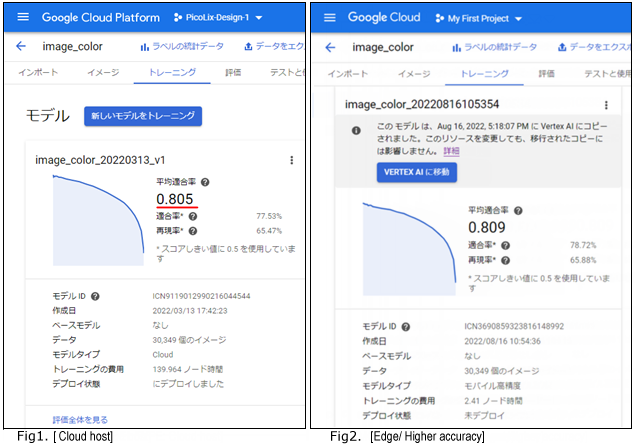
edgeモードでの結果は前回のcloudホストとほぼ同様の結果です。ほんの僅かに適合率が上がっています。
※AutoML Vision 初心者向けガイドに評価結果の見方の解説がありますので参考にしてください。
https://cloud.google.com/vision/automl/docs/beginners-guide?hl=ja
cloudホストモードで実施したときは、139.964ノード時間を費やし、トレーニング用クレジットと無料クレジットを使い果たし、さらに6,000円ほど徴収されました。(1$=114.9円 2022/3時点) [Fig3]
edgeモードで実施した場合は2.41ノード時間でトレーニング時間も4時間程度で済みました。トレーニング用のクレジット無料分で$42消費しただけで、まだ余裕で無料クレジットが残っています。(1$=136.9円 2022/8時点) [Fig4]
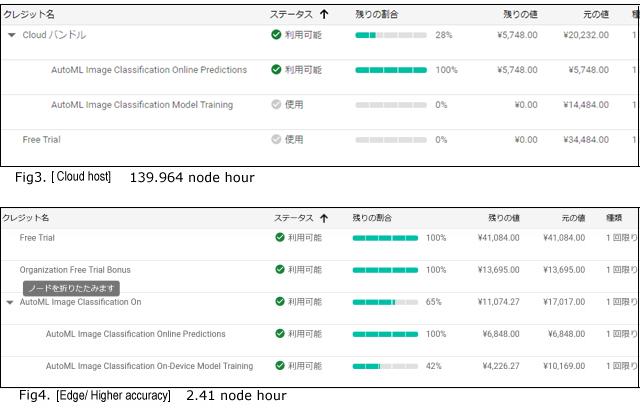
※新規にGoogle Cloud Platform(GCP)を使う場合は無料トライアルとして$300、企業アカウントとして認定された場合は追加で100$、更に初めてAutoMLを使う場合$50(オンライン利用)、$75(トレーニング)が付与されるので十分無料で作成可能です。
※ここ半年で相当な円安になっており、ドルで無料クレジットを取得するとすごく得しているように見えますが、ノード時間はドル課金なので変わりはありません。ただし企業で円で課金する場合は恐ろしく値上げとなります。大量のノード時間を必要とするような場合は大幅な値上げとなります。
学習済みモデルのエクスポート
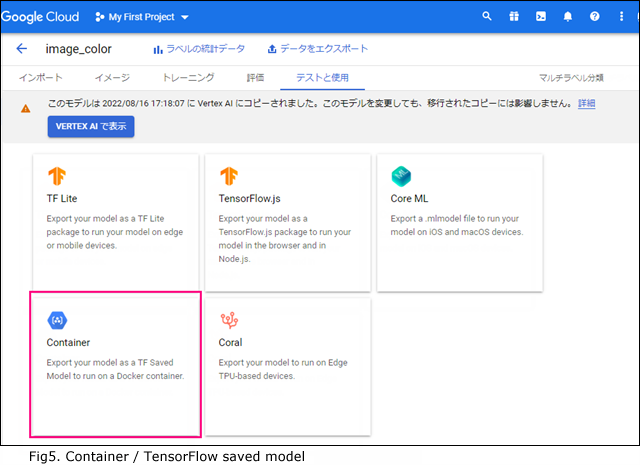
Fig2.のAutoML Vision edgeモードで学習したモデルは、「テストと使用」からエクスポートが選択できます。
TensorFlowで推論を実施したい場合は学習済みモデルsaved_model.pbを利用します。「container」を選択すれば TensorFlowモデル用のsaved_model.pbを取得できます。[Fig5]
「container」はGoogleが用意してくれた専用のDocker(コンテナ型の仮想環境)用ですが、Dockerは使用せず独自の実行環境でTensorFlowを使って検証できます。
イメージカラー学習済みのモデルsaved_model.pbは23Mバイト程度です。高精度でトレーニングしましたが、cloudホストの139.964ノード時間に対して僅か2.41ノード時間のトレーニングとなっているため端末向けにファイルサイズが小さくなっています。次のセクションでこのsaved_model.pbを利用して実際に推論をしていきます。その為にpythonとtensorflowのライブリーが必要となります。
pythonとTensorFlowをインストール
https://www.python.org/からpython-3.10.6-amd64.exe(windows版)をダウンロードしてインストールします。インストール後、cmd画面からpipコマンドで必要なライブラリをインストールしてください。
python.exe -m pip install --upgrade pip pip3 install numpy pip3 install opencv-python pip3 install tensorflow pip3 install argparse
※推論だけですのでNIVIDA系のGPUがなくても計算結果はすぐにでます。
TensorFlowモデルのsaved_model.pb
AutoML Vision edgeモードで作成した画像認識学習済みモデルのsaved_model.pbは、どのような構造なのか。また推論したデータはどう設定すれば良いのか調べてみます。
tensorflowをインストールするとsaved_model_cliコマンドが利用でき、TensorFlowのSaved Modelを確認できます。
c:\apps\ai>saved_model_cli show --dir . --all MetaGraphDef with tag-set: 'serve' contains the following SignatureDefs: signature_def['serving_default']: The given SavedModel SignatureDef contains the following input(s): inputs['image_bytes'] tensor_info: dtype: DT_STRING shape: (-1) name: Placeholder:0 inputs['key'] tensor_info: dtype: DT_STRING shape: (-1) name: Placeholder_1:0 The given SavedModel SignatureDef contains the following output(s): outputs['key'] tensor_info: dtype: DT_STRING shape: (-1) name: Identity:0 outputs['labels'] tensor_info: dtype: DT_STRING shape: (-1, 14) name: Tile:0 outputs['scores'] tensor_info: dtype: DT_FLOAT shape: (-1, 14) name: scores:0 Method name is: tensorflow/serving/predict
・inputデータ内容
①image_bytes(DT_STRING型) 推論したい画像データ
②key(DT_STRING型) 推論するときのユニークキー
・outputデータ内容
③key(DT_STRING型) 推論結果応答キー②を返す
④labels(DT_STRING型) 色名 (イメージカラーを学習させたので、色名のラベル一覧を返す)
⑤scores(DT_FLOAT型) 適応率 (各ラベルに対する適応率を返す)
②のkey(DT_STRING型) はユニーク文字列でなんでもかまいません。これは要求されたセッションに対する応答であるかを判断するためで、非同期に要求と結果を対応させるときによく使う手段で今回はワンショットなので気にしません。
問題は①のimage_bytesがDT_STRING型になっていることです。画像データを渡すことになりますが、文字列型とはどういう扱いでしょうか? バイナリーをHEX文字列で表すのでしょうか?
AutoML Vision edgeモードで「container」はDockerでの利用を前提としています。pythonでのコードが以下に記載があります。
https://cloud.google.com/vision/automl/docs/containers-gcs-tutorial?hl=ja#container-predict-example-python
instances = {
'instances': [
{'image_bytes': {'b64': str(encoded_image)},
'key': image_key}
]
}image_bytesはBASE64で文字列型にしていることがわかりますが、このとおりの文字列で試してみましたがだめでした。これはDocker用に組み込まれたもので、直接利用の場合は違いbyte列の必要があります。例えば2x2ピクセル白色画像のpng形式のバイナリデータは76バイトで以下のようになります。 [Fig6]
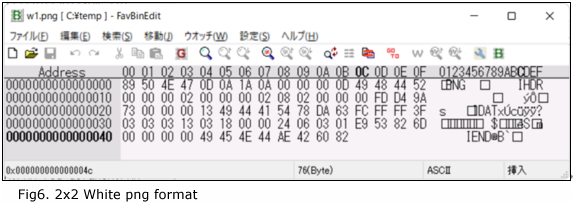
pythonのbyte列では以下のようにbが付くstring型にする必要があります。
b'\x89PNG\r\n\x1a\n\x00\x00\x00\rIHDR\x00\x00\x00\x02\x00\x00\x00\x02\x08\x02\x00\x00\x00\xfd\xd4\x9as\x00\x00\x00\x16IDAT\x08\x1dc\xfc\xff\xff?\x03\x03\x03\xe3\xff\xff\xff\x19\x18\x18\x002\xf0\x05\xfd\xc0Eu\xda\x00\x00\x00\x00IEND\xaeB`\x82'イメージデータをbyte列で渡すだけで良い。次のセクションで実際にプログラミングして推論を行います。
saved_model.pbをロードして推論
pythonでコードはたった30数行です。使い方は、python tfcolor2.py 画像ファイル名1 [画像ファイル名2 …]でイメージカラートップ3が結果として返されます。
tycolor2.py ソースコード
import cv2
import tensorflow as tf
import numpy as np
import argparse
parser = argparse.ArgumentParser(description='')
parser.add_argument('image_path', nargs='+', help='path to image file list')
args = parser.parse_args()
image_path = args.image_path
loaded = tf.saved_model.load(export_dir='./')
print(list(loaded.signatures.keys()))
infer = loaded.signatures["serving_default"]
print(infer.structured_outputs)
imgbytes = list()
for path in image_path:
img = cv2.imread(path)
rst,bts = cv2.imencode('.png', img)
imgbytes.append(bts.tobytes())
out = infer(key=tf.constant('uniq_dummy_id_123'), image_bytes=tf.constant(imgbytes))
print(out)
scores = out["scores"]
labels = out["labels"]
num = scores.numpy().shape[0]
for j in range(num):
top = np.argsort(-scores.numpy()[j])
print(image_path[j])
for i in range(3):
print('%d: %-7.6f : %s' % (i + 1,scores.numpy()[j][top[i]], labels.numpy()[j][top[i]].decode('utf-8')))
・6~9行:画像ファイルを複数指定できるように、argparseで引数を取得しています。
・11行:tf.saved_model.loadで学習済みモデルsaved_model.pbをロードします。ファイル名は固定で、saved_model.pbが存在する ディレクトリーをパラメータに指定します。
・14行:loaded.signatures["serving_default"]でdict型(辞書の型)として変数inferに返されます。
・20行:cv2.imencodeでbtsにnumpyの配列で返されます。先ほどの2x2の白画像(png)の場合は
[137 80 78 71 13 10 26 10 0 0 0 13 73 72 68 82 0 0
0 2 0 0 0 2 8 2 0 0 0 253 212 154 115 0 0 0
22 73 68 65 84 8 29 99 252 255 255 63 3 3 3 227 255 255
255 25 24 24 0 50 240 5 253 192 69 117 218 0 0 0 0 73
69 78 68 174 66 96 130]・21行:tobytes()関数でbyte列に変換します。
b'\x89PNG\r\n\x1a\n\x00\x00\x00\rIHDR\x00\x00\x00\x02\x00\x00\x00\x02\x08\x02\x00\x00\x00\xfd\xd4\x9as\x00\x00\x00\x16IDAT\x08\x1dc\xfc\xff\xff?\x03\x03\x03\xe3\xff\xff\xff\x19\x18\x18\x002\xf0\x05\xfd\xc0Eu\xda\x00\x00\x00\x00IEND\xaeB`\x82'・21行:複数画像がある場合は繰り返して、imgbytesに配列で保管します。
・23行:infer(key=tf.constant('uniq_dummy_id_123'), image_bytes=tf.constant(imgbytes)) キーとイメージデータを渡すと推論結果が得られます。
例1)青系のドラゴン画像[Fig7]と赤系のドラゴン画像[Fig8]のイメージカラーの推論
c:\apps\ai>python tfcolor2.py blue-doragon.png red-doragon.png
['serving_default']
{'labels': <tf.Tensor 'Tile:0' shape=(None, 14) dtype=string>,
'scores': <tf.Tensor 'scores:0' shape=(None, 14) dtype=float32>,
'key': <tf.Tensor 'Identity:0' shape=(None,) dtype=string>}
{
'labels': <tf.Tensor: shape=(2, 14), dtype=string, numpy=
array([[b'orange', b'yellow', b'purplish_red', b'green', b'gray',
b'yellow_green', b'purple', b'pink', b'red', b'black', b'white',
b'blue_green', b'blue', b'brown'],
[b'orange', b'yellow', b'purplish_red', b'green', b'gray',
b'yellow_green', b'purple', b'pink', b'red', b'black', b'white',
b'blue_green', b'blue', b'brown']], dtype=object)>,
'scores': <tf.Tensor: shape=(2, 14), dtype=float32, numpy=
array([[0.05143434, 0.0465448 , 0.3964859 , 0.0465448 , 0.05680693,
0.04539329, 0.07087733, 0.05016822, 0.04893166, 0.05823032,
0.04003182, 0.5781289 , 0.7745404 , 0.2492084 ],
[0.03903484, 0.04772406, 0.67595094, 0.0924189 , 0.04539329,
0.05968711, 0.39022017, 0.10650936, 0.07087733, 0.05405774,
0.04539329, 0.08602025, 0.230078 , 0.60351413]], dtype=float32)>,
'key': <tf.Tensor: shape=(), dtype=string, numpy=b'uniq_dummy_id_123'>}
・23行:2画像のデータを渡しているので2つの結果が配列でかえってきます。
・29~34行:labels順とscore順は対応していますので、見やすいようにここからTOP3を取得します。-scoresとすると降順でソートします。
イメージから抽出結果:
blue-doragon.png
1: 0.774540 : blue
2: 0.578129 : blue_green
3: 0.396486 : purplish_red
red-doragon.png
1: 0.675951 : purplish_red
2: 0.603514 : brown
3: 0.390220 : purple
※結果の表示は見やすいように適宜改行および色を付けています。
GCP Auto ML上で推論した結果:[Fig9]

似たような結果です。Auto ML上では色はTOP2まで表示されます。
例2)イチゴの錯視画像[Fig10] も推論してみましょう。人には赤く見えますがAIではそこまで分かりません。

Fig10. 出典:「赤く見えるいちご」http://www.psy.ritsumei.ac.jp/~akitaoka/color16.htmlより
この画像には赤系の色は使われていませんが人間には錯視効果で赤く見えています。このような錯視効果は今回の学習済みモデルでは全く配慮されていませんので当然、青、緑系の結果がでます。
c:\apps\ai>python tfcolor2.py ichigo-red-or-green.jpg
['serving_default']
{'key': <tf.Tensor 'Identity:0' shape=(None,) dtype=string>,
'scores': <tf.Tensor 'scores:0' shape=(None, 14) dtype=float32>,
'labels': <tf.Tensor 'Tile:0' shape=(None, 14) dtype=string>}
{
'key': <tf.Tensor: shape=(), dtype=string, numpy=b'uniq_dummy_id_123'>,
'scores': <tf.Tensor: shape=(1, 14), dtype=float32, numpy=
array([[0.05541629, 0.05968711, 0.06916751, 0.37779844, 0.03903484,
0.07087733, 0.05823032, 0.04893166, 0.0465448 , 0.05968711,
0.04893166, 0.85638064, 0.6816758 , 0.09464505]], dtype=float32)>,
'labels': <tf.Tensor: shape=(1, 14), dtype=string, numpy=>
array([[b'orange', b'yellow', b'purplish_red', b'green', b'gray',
b'yellow_green', b'purple', b'pink', b'red', b'black', b'white',b'blue_green',
b'blue', b'brown']], dtype=object)>}
ichigo-red-or-green.jpg
1: 0.856381 : blue_green
2: 0.681676 : blue
3: 0.377798 : green
GCP Auto ML上で推論した結果も載せておきます。[Fig11]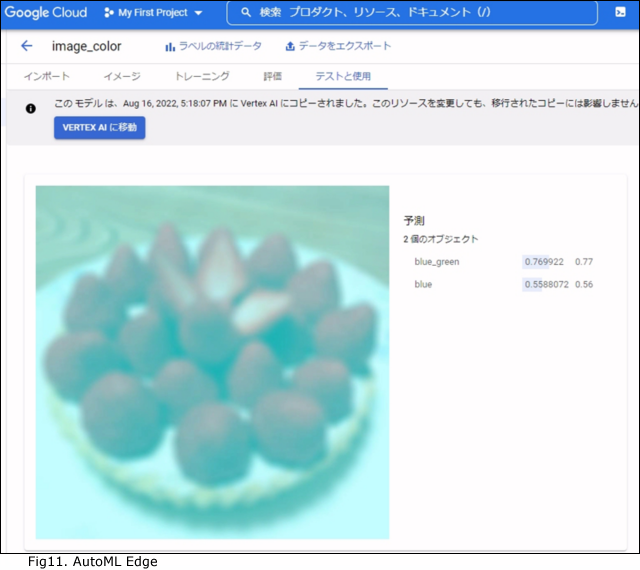
AIといえども学習モデルありきです。錯視のパターンも多数用意して学習すれば判別できるかもしれません。
最後に
クラウド側で時間のかかる学習を行って得られた学習済みモデルを端末側に一度配信しておけば、端末側でクラウドへの問い合わせによる時間ロスもなく推論が即座にできます。これがエッジAIの良いところです。
GCP Auto MLで学習した学習済みモデルを利用されたい方の参考になればと思います。
推論部分をプログラミングするとトレーニング、評価もクラウドではなくて自分で実施して学習済みモデルを作成したくなってくると思います。TensorFlow, Keras,VGG16を利用したマルチラベル分類も筆者では作成しておりますが、まだ検証段階です。いずれかの機会に公開したいと思います。(なおこの場合は計算に時間がかかるのでNIVIDA系GPUが必須です)
ドメインが実質0円(年間最大3,889円お得)になるサーバーセット割特典を展開中です。
最新のキャンペーンはこちらから

※ユーザーノートの記事は、弊社サービスをご利用のお客様に執筆いただいております。
医療メーカーで新素材研究開発後、電機メーカーで制御器系システム開発を経てIT系マルチエンジニアをしています。またデザイン思考を実践し、アート思考などのいろんな思考方法に興味があります。






 目次へ
目次へ